AI声音克隆实战:一步步教你如何训练出专业的声音模型
嫌啰嗦,可直接跳至教程学习界面
序言
音乐是一种跨越语言和文化的艺术形式,能够带给人们美的享受和情感的共鸣。然而,对于一些五音不全的人来说,歌唱成为一种难以逾越的障碍。但是,随着人工智能技术的不断发展,我们现在有了AI声音模型克隆技术,这项技术能为五音不全的人们带来新的体验。
AI声音模型克隆技术是一种利用深度学习算法,根据目标声音的特点和参数,生成与之相似的新声音。这种技术已经被广泛应用于声音模拟、声音转换、歌唱合成等领域,为音乐创作和教育提供了更多的可能性和便利。
本文将介绍AI声音模型克隆技术的概念、优点和实际应用场景,并探讨潜在的问题和未来的发展方向。同时,我还将提供一些声音模型网站的注册方式和相关信息,以便读者能够更好地了解和尝试这种技术。
尽管本文有一定难度,但只要勇于尝试,问题总会迎刃而解。
技术原理
AI声音模型训练是通过分析大量音频数据来学习声音特性,生成与目标声音相似的新音频。这包括数据预处理、模型构建、训练、评估和优化。为了达到逼真、自然的声音效果,需要大量高质量音频数据和计算资源,并且需要精细调整和优化模型。
教程开始阶段
准备阶段
训练AI声音需要准备以下两部分:
1,高质量的音频数据:这是训练声音模型的基础,需要收集和准备大量的音频数据,包括不同人的发音、不同的声音特征等。这里音频数据指的是说话人的干声,干声就是无伴奏无杂音和背景音乐的说话声,也可以包括歌曲清唱的声音。所需时间 1小时左右声音
这里我放上几个可以朗读的文字,按照以下文字清晰朗读,方便学习不同的音高和音色。如果要训练唱歌的模型,请自己准备好歌词清唱


2,硬件资源:训练声音模型需要大量的计算资源,包括高性能的计算机、GPU等。白话说就是显卡要好。一般 英伟达2060 TI 8Gb以上的就可以进行运算了,只不过耗时巨慢,也可以自己在显卡租用平台,进行租用,价格 1元多1小时。一般 6个小时,就可以把模型训练出来。本文只教学 本地推理,如果本地电脑配置不高的朋友想学云端训练,我会再写下教程。
(本文不涉及任何推广)
训练介绍
RVC介绍
Retrieval-based-Voice-Conversion-WebUI 简称 RVC
一个基于VITS的简单易用的语音转换(变声器)框架
RVC0813 整合包下载(整合包 包含 运行环境 启动器)
https://pan.baidu.com/s/1mEs9Jmi2tBot4AgH6ZWp-w?pwd=eqea
特点
- 使用top1检索替换输入源特征为训练集特征来杜绝音色泄漏
- 即便在相对较差的显卡上也能快速训练
- 使用少量数据进行训练也能得到较好结果(推荐至少收集10分钟低底噪语音数据)
- 可以通过模型融合来改变音色(借助ckpt处理选项卡中的ckpt-merge)
- 简单易用的网页界面
- 可调用UVR5模型来快速分离人声和伴奏
- 使用最先进的人声音高提取算法InterSpeech2023-RMVPE根绝哑音问题。效果最好(显著地)但比crepe_full更快、资源占用更小
- A卡I卡加速支持
教程阶段,可直接在此处学习
一、将整合包下载并解压,启动go-web.bat 等待运行
RVC0813 整合包下载(整合包 包含 运行环境 启动器)
https://pan.baidu.com/share/init?surl=mEs9Jmi2tBot4AgH6ZWp-w&pwd=eqea
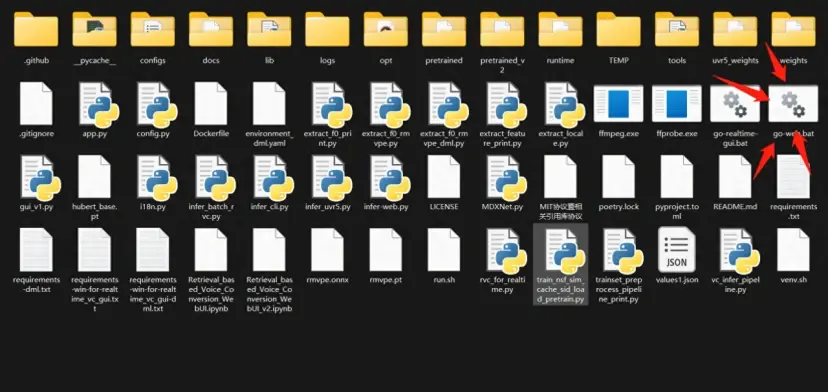
启动go-web.bat
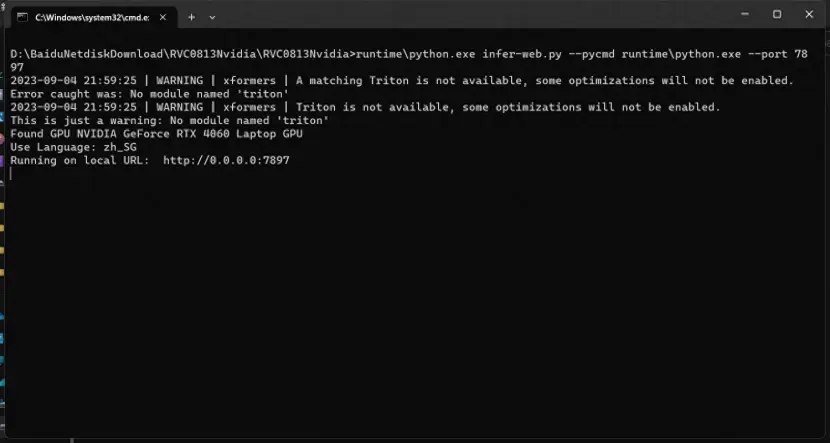
出现0.0.0 启动成功
二、进入训练界面,默认的参数默认就行,不用动
3,输入音频文件夹路径,处理数据
将要训练的的干声数据集放到本地任意英文路径文件夹内复,点击处理数据
处理数据
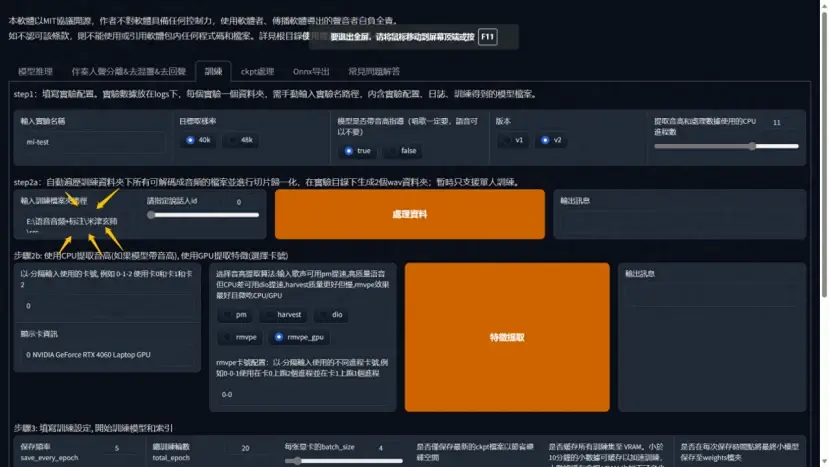
输入 音频文件夹路径
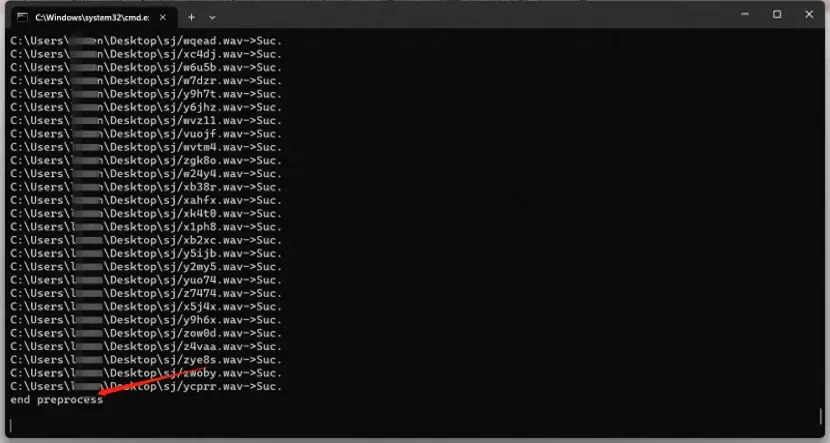
处理完毕
出现 end preprocess 表示处理完毕
特征提取
(特征提取是从声音信号中提取有用信息的过程,这些信息可以被用于训练模型进行分类或识别)
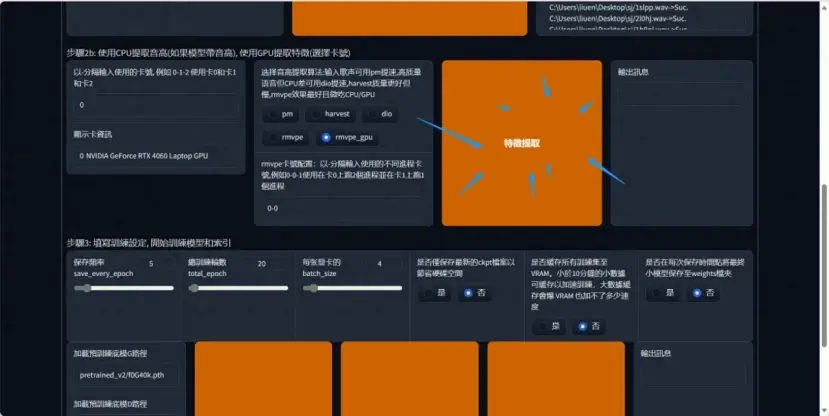
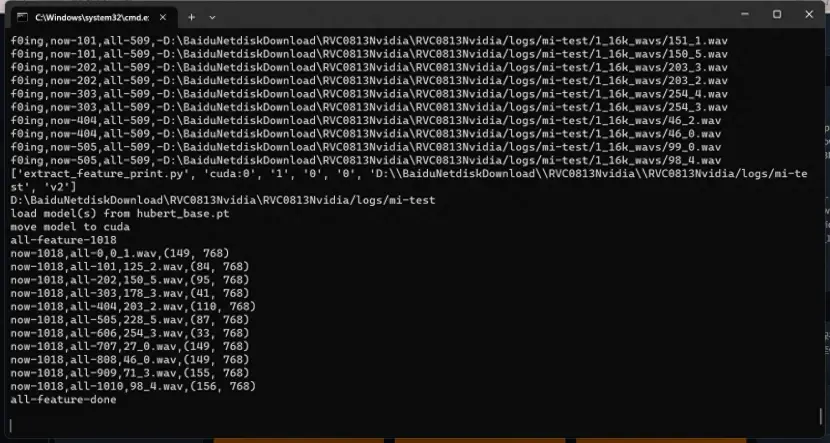
处理完毕
出现 all-feature-done 表示已经处理完毕,可以进行最后一步处理了
最后一步,开始训练,设置训练的步数和保存频率
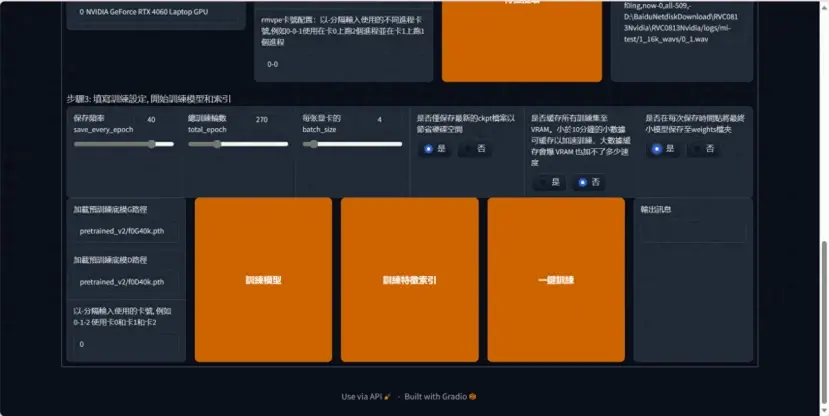
数值参数设置
保存頻率 这个数值表示多少轮保存一次模型,如果你的电脑很牛很稳定 50轮也是可以的,不然就推荐 20-40轮保存一次模型
總訓練輪數一般 300轮模型就可以出炉了
每张显卡的batch_size 如果你的显存是8则填8,显存多少,填多少数值。
点击一键训练

终端显示Epoch: 1字符,表示第一轮,正在训练了
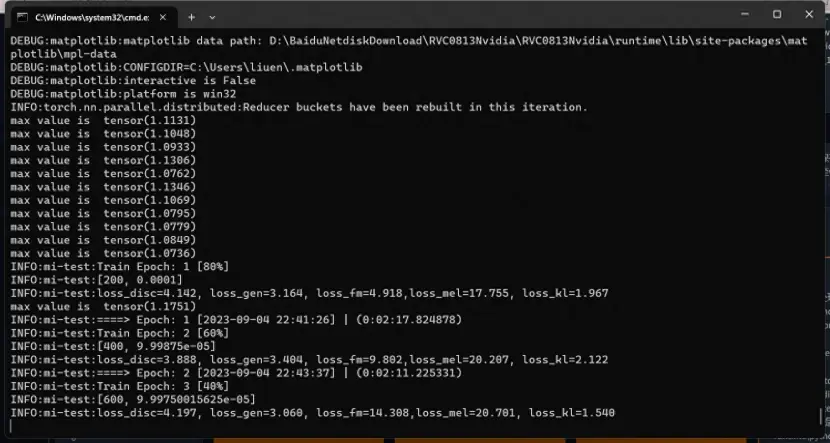
正在训练
等待几个小时后,就训练结束了,就可以进行下一步,对声音模型进行推理试音了。
准备好要换音的音频,选择音频推理,找到自己已经训练好的模型音色
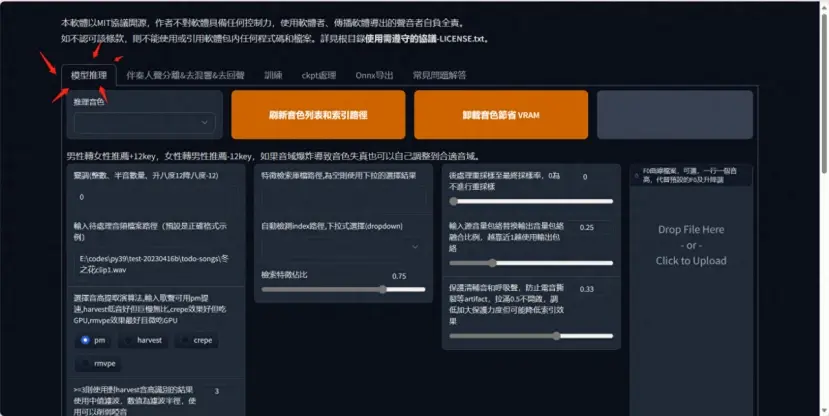
选择轮数模型
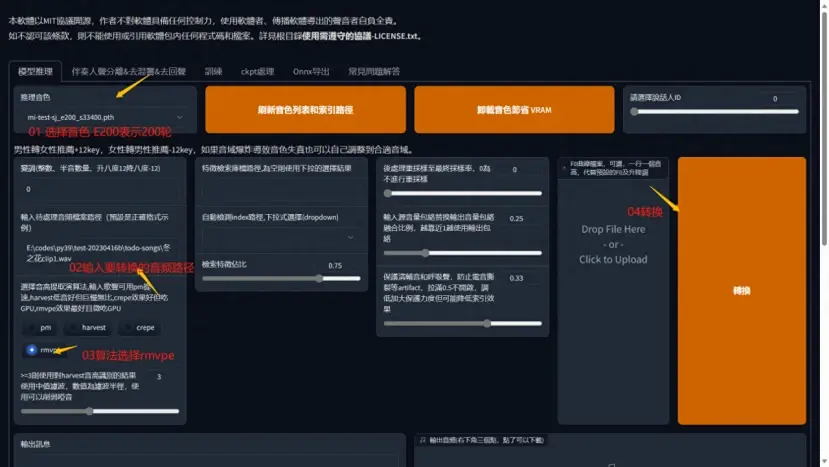
声音转换
我训练的是舌尖上的中国配音试听一下。

到此为止,模型训练完毕,不会的可留言指导。
声音模型下载
推荐一个声音模型下载网站,模型工坊网址 mxgf.cc
有很多高质量声音模型,目前还是在一直更新中,有免费和收费的模型,对比我们来训练的话,还是很省时省力
下载一个RVC模型测试
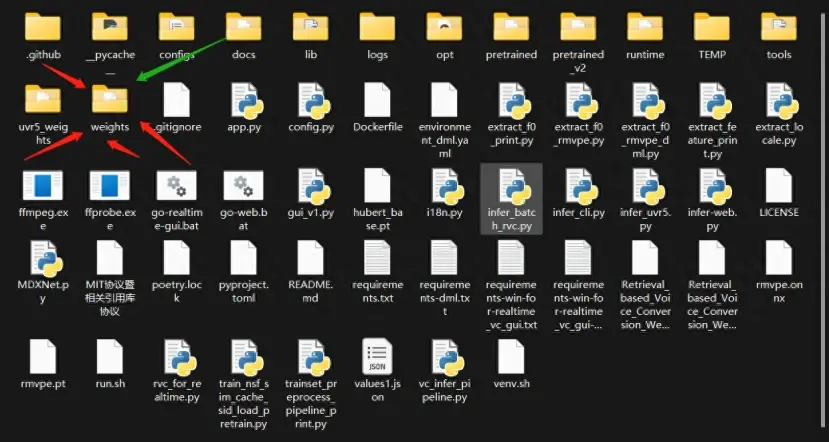
将下载好的声音模型文件,放置到 RVC目录下的 weights 目录下
模型工坊 mxgf.cc
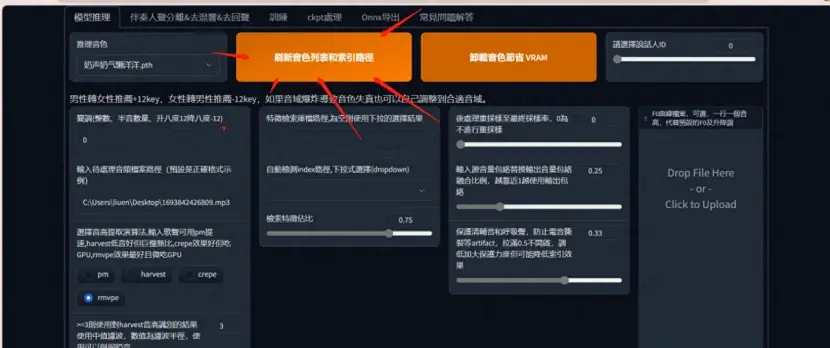
进入 WEBUI 界面 刷新音色
将要转换的声音或者歌曲干声转换,然后和伴奏合并,试听一下
到此文章结束,有任何疑问欢迎提问。